##
## Container Image 목록 조회하기
##
$ curl -X GET http://192.168.2.2:5000/v2/_catalog
##
## 특정 Image의 tag list 조회하기
##
$ curl -X GET http://192.168.2.2:5000/v2/almighty/tags/list
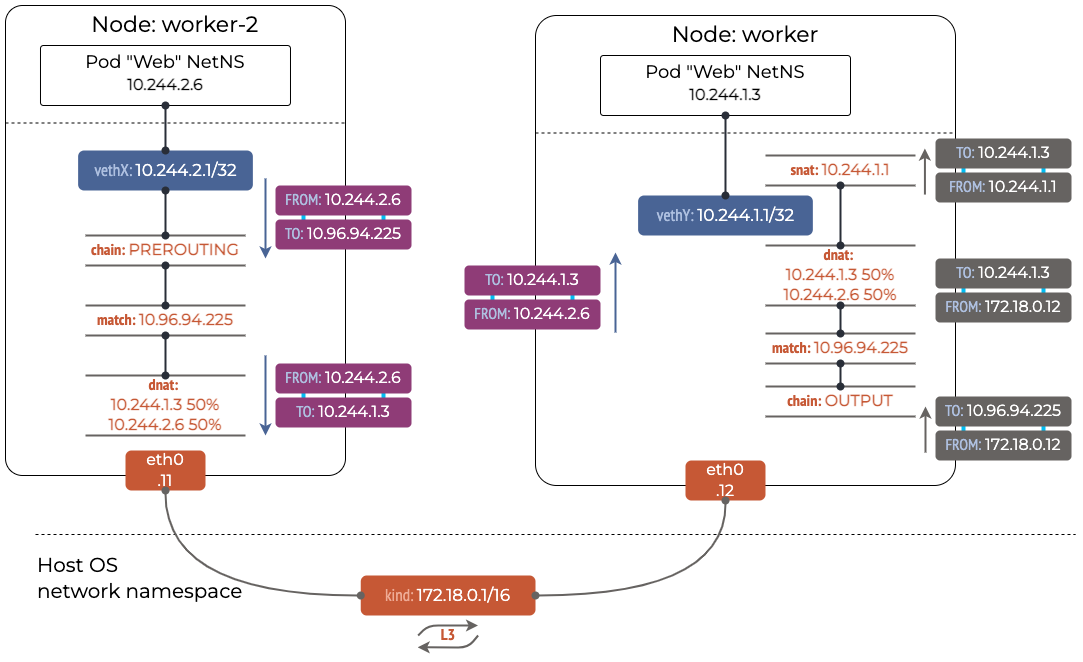
Kubernetes Cluster에서 MetalLB를 사용하다 보면, IP 트래픽을 처리하는 방식이 궁금할 때가 많다.
특히 Baremetal 환경에서 서비스를 운영한 개발자, 운영자라면 특히나 MetalLB의 동작 방식이나 원리가 이해가 안 되고, 감(느낌)도 안 잡힌다.
어디에 MetalLB 설계서 같은 문서가 있으면 좋겠지만, 그런게 없으니까 일단 궁금한 점이 떠오를 때마다 테스트하고 기록하는 수 밖에 ~~~
Q) Kubernetes Service 리소스의 External IP 항목에 보여지는 IP Address는 실제로 어디에 있는가?
실제로 LoadBalancer Type으로 서비스 리소스를 설정하고, External IP Address를 할당받아서 테스트를 해보니까,
External IP Address는 Master Node 또는 Worker Node에 있는 특정한 Network Port(예: eth2)의 Mac Address를 공유해서 쓰고 있었다.
물론 Network Port(예: eth2)는 External IP Address와 같은 Network 대역이라서 라우팅이 가능한 Port가 된다.
(아마 MetalLB Operator가 동일한 Network 대역을 찾아서 할당해주는 것 같다)
참고: Layer 2 Mode로 MetalLB를 구성하고 테스트한 결과임
그렇다면, Master Node와 Worker Node가 10개가 있을 때, 어떤 Master Node와 Worker Node에 External IP Address가 있게 되는걸까?
이 External IP Address와 관련있는 Pod의 위치(Pod가 구동된 Master Node 또는 Worker Node)와는 전혀 관련이 없다.
MetalLB는 External IP Address를 Worker Node의 특정 Ethernet Port에 할당할 때, 최대한 분산되도록 스케쥴링한다.
만약 MetalLB가 External IP를 worker-a에 이미 할당할 것이 있다면, 그 다음 External IP를 worker-a가 아닌 다른 Node에 위치하도록 구성한다. 즉, 이 External IP가 한쪽 Kubernetes Node에 몰려서 외부 트래픽이 한개의 Node에 집중되는 것을 막으려는 노력을 하는 것이다.
주의: 위 문서가 대체로 절차를 잘 설명하고 있지만, ServiceMonitor 리소스에 대한 설정이 이상하다. 그래서 ServiceMonitor 리소스는 내가 별도로 만들었다.
웹 문서의 설명과 다른 부분만 아래와 같이 Comment를 추가했다.
Comment가 붙어 있는 라인만 잘 수정하면, 잘 동작한다.
##
## File name: servicemonitor.yaml
##
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: almighty
name: almighty
namespace: openshift-monitoring ## Note: 반드시 이 namespace로 설정해야 한다.
spec:
endpoints:
- interval: 15s
port: web
scheme: http
path: /metrics ## 이 설정을 꼭 넣자.
selector:
matchLabels:
app: almighty ## 이 부분이 Pod, Service의 label 값과 같은지 꼭 확인해야 한다.
namespaceSelector:
matchNames:
- almighty ## Service 리소스의 값과 같은지 확인해야 한다.
servicemonitor.yaml 파일을 작성하면, 아래와 같이 kubectl 명령으로 kubernetes cluster에 적용한다.
$ kubectl apply -f servicemonitor.yaml
그런데 여기서 생각해볼 것이 있다. 만약, Service에 포함된 Pod가 2개 이상일 때는 위 ServiceMonitor처럼 Scrapping을 시도하면 2개의 Pod 중에서 1개의 Pod만 Scrapping에 응답하기 때문에 반쪽 짜리 Scrapping이 되는 문제가 있다. Pod가 10개라면, 1개 Pod 입장에서 본다면 Scrapping 인터벌(주기)는 10배로 더 길어진다.
따라서 Service에 포함되는 Pod가 2개 이상일 때는 ServiceMonitor 보다 PodMonitor 조건을 사용하는 것이 좋다. PodMonitor를 사용하면, Prometheus가 각 Pod마다 접근해서 Scrapping한다.
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: almighty
labels:
app: almighty
## FIXME
namespace: openshift-monitoring
spec:
selector:
matchLabels:
## FIXME
app: almighty
podMetricsEndpoints:
## FIXME
- port: web
path: /metrics
interval: 7s ## 테스트를 해보면, 1s 로 설정해도 잘 동작한다.
scheme: http
namespaceSelector:
matchNames:
## FIXME
- almighty
Prometheus Web UI를 열고, 아래와 같이 Qeury(PromQL)을 입력한다.
## Example 1
http_request_duration_seconds_bucket{code="200",handler="found"}
## Example 2
irate(http_requests_total{namespace="almighty", code="200"}[5m])
irate 함수를 사용한 PromQL
위와 같이 챠트가 잘 그려지면, Prometheus의 Scraper가 사용자 App의 Metrics을 잘 Scraping하고 있는 것이다.
만약, Kubernetes 또는 OCP를 초기 구축하고 나서 User App에 대한 Metrics을 Scrapping할 수 있는 Role을 Prometheus ServiceAccount에 부여하지 않았다면, 꼭 Cluster Role과 ClusterRoleBinding을 설정해줘야 한다.
이 Cluster Role Binding 작업이 안 되어 있으면, 위에서 예제로 설명했던 ServiceMonitoring, PodMonitoring을 모두
"endpoints is forbidden" 에러가 발생할 것이다. (아래 Error Log을 참고)
Prometheus Error Log 예시
$ kubectl logs -f -n openshift-monitoring prometheus-k8s-0
ts=2022-08-10T03:29:51.795Z caller=log.go:168 level=error component=k8s_client_runtime func=ErrorDepth msg="github.com/prometheus/prometheus/discovery/kubernetes/kubernetes.go:471: Failed to watch *v1.Pod: failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:openshift-monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" in the namespace \"almighty\""
위 에러를 없애기 위해 아래와 같이 ClusterRole, ClusterRoleBinding 리소스를 만들어야 한다.
Kubernetes, OCP(Openshift Container Platform)을 사용하다 보면, Resource에 대한 접근 권한 때문에 답답한 경우가 많다.
SCC(SecurityContext)를 잘 관리할 줄 알면, 제일 좋지만 급하게.. 그리고 간단하게 테스트만 하는 상황이라면,
아래와 같이 시스템의 모든 자원에 접근할 수 있도록 권한을 최고 수준(privileged)으로 올려주고 테스트하는 것이 정신 건강에 좋다.
(상용 서비스에서는 절대 이렇게 하면 안 된다. Test bed 같은 곳에서 잠깐 Feasibility check만 하고 Pod를 종료시킨다는 가정하에 사용할 것)
apiVersion: v1
kind: Pod
metadata:
name: my-example-pod
spec:
hostNetwork: true ## <-- 이 설정이 있으면, Pod 내부에서 Host Network이 보인다
## 예를 들어, Host OS의 eno3 network port를 보기 위해
## ifconfit eno3 명령 실행이 가능해진다.
containers:
...
securityContext:
privileged: true ## <-- 이렇게 하면 모든 자원에 접근 가능해진다.
...
securityContext: {}
...
만약, 극단적으로 Pod 내부에 있는 Process가 Host OS의 자원에 제약 없이 접근하고 싶다면 아래 예제 YAML처럼 권한 설정을 하면 된다. 이렇게 하면, Pod 내부에서 Pod 밖(즉 Host OS)의 IP network 자원, TCP Stack, IPC, ProcessID(PID) 등에 자유롭게 접근할 수 있다.
다시 한번 강조하지만, 위와 같이 securityContext.privileged: true 설정된 Pod를 상용 서비스를 제공하는 클러스터에서 구동한 상태로 오래 방치하면 결국 해커의 먹이감이 된다. 꼭 10분~20분 정도 테스트만 하고 바로 Pod를 종료(삭제)해야 한다.
아래 내용은 참고용으로만 볼 것!!!
DaemonSet으로 구동하는 Pod들은 securityContext 값이 privileged 으로 설정된 경우가 많다.
왜냐하면 이런 DaemonSet으로 구동된 Pod들은 각 노드에서 Host 자원에 접근해야 하는 경우가 있기 때문이다.
아래 예시를 보면 바로 이해가 될것이다.
Multus 배포 예시
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: multus
namespace: openshift-multus
... 중간 생략 ...
spec:
template:
... 중간 생략 ...
spec:
containers:
... 중간 생략 ...
securityContext:
privileged: true ## <-- 이 부분
... 중간 생략 ...
Openshift SDN 배포 예시
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: sdn
... 중간 생략 ...
spec:
template:
... 중간 생략 ...
spec:
containers:
... 중간 생략 ...
securityContext:
privileged: true ## <-- 이 부분
... 중간 생략 ...