일반적으로 물리 네트워크 포트 1개에는 MAC address 1개, IP address 1개를 설정해서 사용한다.
(본업으로 Network 장비를 개발, 운영하는 사람이 아니라면 이런 단순한 구성이 익숙할 듯)
그런데 물리 네트워크 포트 1개에 '마치 여러 개의 네트워크 포트가 있는 것처럼' 동작하게 만들어야 할 때가 있다.
예를 들어,
- 물리 포트 eth0에 2개 이상의 MAC address를 설정
- 물리 포트 eth0에 2개 이상의 IP address를 설정
위 2가지를 모두 지원하는 가상 포트 타입이 'MACVLAN'이다.
[참고: Hypervisor, Virtual Machine Manager 에서 VM이 사용할 NIC 포트를 Bridge 타입으로 설정하면 위와 같은 형상이 된다)
Bridge 모드의 MACVLAN 포트 동작 방식 (출처: Red Hat Developer Blog)
아래 예시 명령과 같이 따라해보면 바로 이해가 될 듯.
(명령을 실행했던 OS: Ubuntu 22.04)
## 물리 NIC 포트 'eth0'에 IP address 설정
ip address add 10.1.4.55/24 dev eth0
## 물리 포트 'eth0'에 가상 포트 'macvlan1'을 만들기
ip link add macvlan1 link eth0 type macvlan mode bridge
## network namespace 'net1' 만들기
ip netns add net1
## network namespace 'net1'에 가상 포트 'macvlan1'을 추가
ip link set macvlan1 netns net1
## 가상 포트 'macvlan1'을 활성화(up)하기
ip netns exec net1 ip link set dev macvlan1 up
## 가상 포트에 IP address를 설정
ip netns exec net1 ip address add 10.1.4.51/24 dev macvlan1
## IP 통신이 잘 되는지 'ping test'하기
ip netns exec net1 /usr/bin/ping 10.1.4.56
## 테스트 종료, 가상 포트 'macvlan1' 지우기
ip netns exec net1 ip link del macvlan1
위 예시에서 'mode bridge'로 설정한 부분이 있는데, bridge 모드 외에도 아래와 같은 다양한 모드를 설정할 수 있다.
참고 문서: https://pr0gr4m.github.io/linux/kernel/netfilter/ 이론 설명과 함께 잘 동작하는 예시가 있어서 쉽게 이해할 수 있다. 아래는 위 블로그의 끝 부분에 있는 HTTP Traffic만 선별하여 Drop하는 예제 코드인데, 그냥 이 예제 코드만 봐도 이해할 수 있을 것이다.
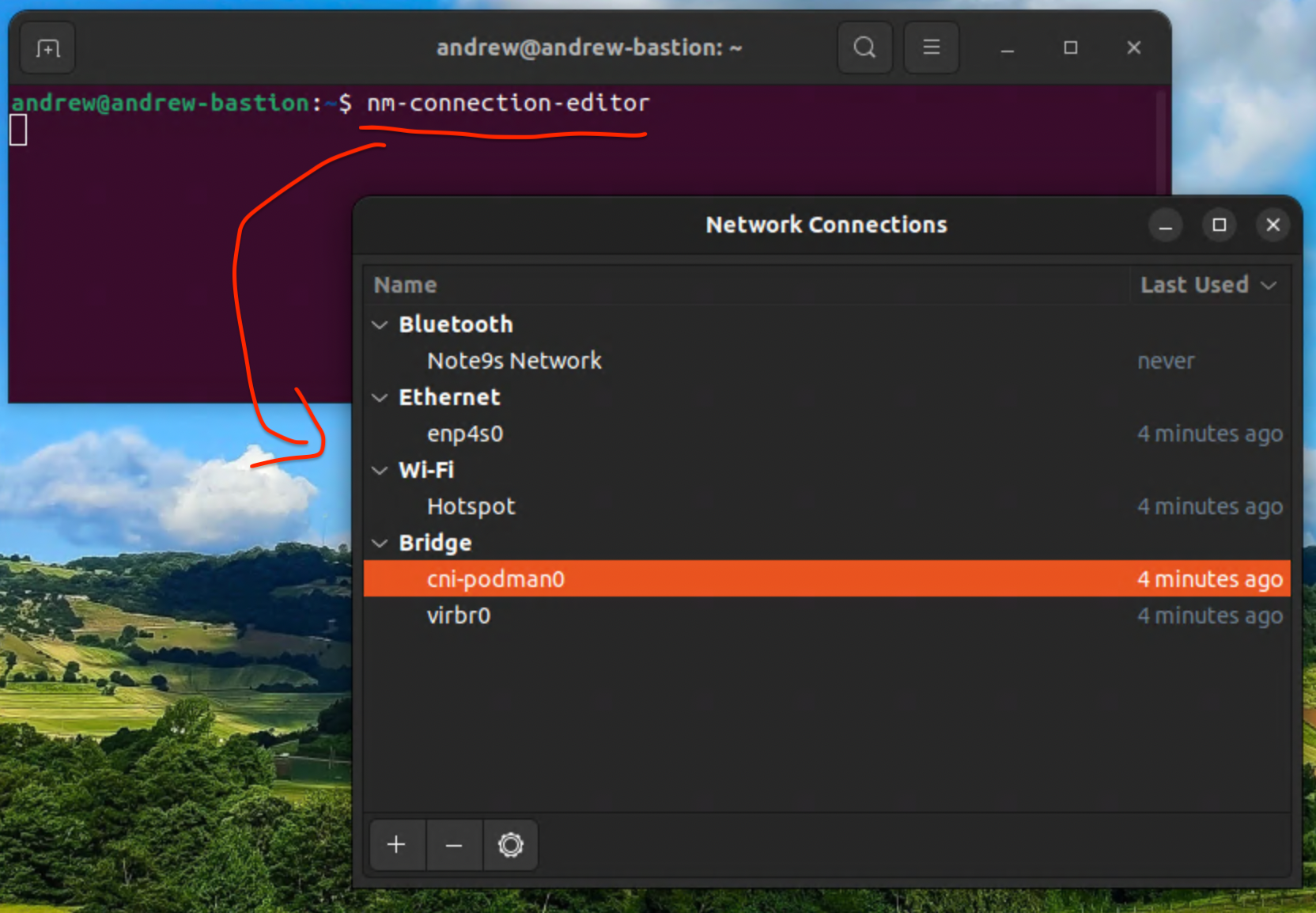
Ubuntu OS를 설치한 후, Network 구성을 바꿀 때 nmtui, netplan, nm-connection-editor 등 CLI 명령을 사용하면 쉽게 network 구성을 설정할 수 있다.
nmtui 명령
메모: 지금은 바빠서 설명을 생략. 나중에 내용을 추가할 것 !!
$ nmtui
Text Terminal에서 위 명령을 수행하면, 아래와 같이 동일 Text Terminal에서 TUI가 뜬다.
nmtui 시작 화면
netplan 명령
길게 설명하는 것보다는 아래 예시를 보고 이해하고 따라하는 것이 좋을 듯 ~~~
Case A: 만약 Gnome Desktop GUI의 [ Settings ] - [ Network ] - [ Wired ] 화면에서 설정하고 싶으면, 아래와 같이 renderer를 NetworkManager로 지정하고 아무것도 설정하지 않으면 된다. 그러면 NetworkManager가 알아서 Physical Network Device를 찾아서 Profiling할 것이다.
Case B: 만약 Gnome Desktop GUI의 [ Settings ] - [ Network ] - [ Wired ] 화면에서 설정한 값을 무시하고 설정 파일에 있는 Network Config를 적용하고 싶다면, 아래와 같이 renderer를 networkd 로 지정한다. 그런 후에 원하는 설정을 추가한다.
Kubernetes Cluster에서 MetalLB를 사용하다 보면, IP 트래픽을 처리하는 방식이 궁금할 때가 많다.
특히 Baremetal 환경에서 서비스를 운영한 개발자, 운영자라면 특히나 MetalLB의 동작 방식이나 원리가 이해가 안 되고, 감(느낌)도 안 잡힌다.
어디에 MetalLB 설계서 같은 문서가 있으면 좋겠지만, 그런게 없으니까 일단 궁금한 점이 떠오를 때마다 테스트하고 기록하는 수 밖에 ~~~
Q) Kubernetes Service 리소스의 External IP 항목에 보여지는 IP Address는 실제로 어디에 있는가?
실제로 LoadBalancer Type으로 서비스 리소스를 설정하고, External IP Address를 할당받아서 테스트를 해보니까,
External IP Address는 Master Node 또는 Worker Node에 있는 특정한 Network Port(예: eth2)의 Mac Address를 공유해서 쓰고 있었다.
물론 Network Port(예: eth2)는 External IP Address와 같은 Network 대역이라서 라우팅이 가능한 Port가 된다.
(아마 MetalLB Operator가 동일한 Network 대역을 찾아서 할당해주는 것 같다)
참고: Layer 2 Mode로 MetalLB를 구성하고 테스트한 결과임
그렇다면, Master Node와 Worker Node가 10개가 있을 때, 어떤 Master Node와 Worker Node에 External IP Address가 있게 되는걸까?
이 External IP Address와 관련있는 Pod의 위치(Pod가 구동된 Master Node 또는 Worker Node)와는 전혀 관련이 없다.
MetalLB는 External IP Address를 Worker Node의 특정 Ethernet Port에 할당할 때, 최대한 분산되도록 스케쥴링한다.
만약 MetalLB가 External IP를 worker-a에 이미 할당할 것이 있다면, 그 다음 External IP를 worker-a가 아닌 다른 Node에 위치하도록 구성한다. 즉, 이 External IP가 한쪽 Kubernetes Node에 몰려서 외부 트래픽이 한개의 Node에 집중되는 것을 막으려는 노력을 하는 것이다.