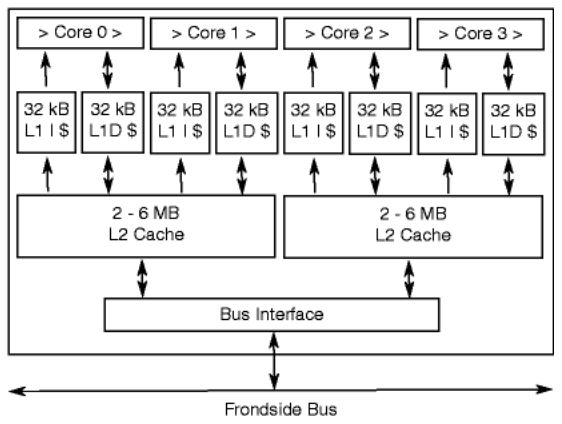
X86_64 CPU는 아래 그림처럼 1개의 물리 Core가 2개의 논리 CPU(Thread)로 구성되어 있고, 이 2개의 논리 CPU(Thread)가 1개의 L2 Cache를 공유하기 때문에 만약 홀수 개로 CPU를 Pinning(즉, Isolation)하면, L2 Cache의 Hit Ratio가 확 떨어지기 때문에 Core의 처리 속도가 겁나게 떨어진다는 것이다.
즉, L2 Cache 1개를 두고 LCore-0과 LCore-1이 치고 박고 시끄럽게 싸우는 꼴~~~ X86_64 CPU 구조에는 늘상 발생하는 현상으로써, "noisy neighbors"라고 표현한다.
쉽게 이해하기 위해 일상 생활과 비유해본다면,
2명의 사람이 한 집에 살면서 요리를 하는데
주방이 1개라서 홍길동은 된장찌개(Job-A)를 만들어 먹고 싶고, 이순신은 김밥(Job-B)을 만들어 먹고 싶다면
홍길동이 된장찌개 요리를 마무리하고 주방(L2 Cache)를 비워줘야, 이순신이 그 주방(L2 Cache)에서 김밥을 만들 수 있는 것과 같다.
여기서 핵심은 "주방(L2 Cache)를 비워줘야" 한다에 있다.
Local Thread가 서로 다른 일을 할 경우, L2 Cache에 담을 내용이 서로 다르기 때문에 L2 Cache 메모리에 있는 데이터를 재사용할 수 없고(즉, Hit Ratio가 떨어지고) 실제 L2 Cache는 Cache 로써의 역할을 못하게 된다.
L2 Cache의 내용 싹~~~ 갈아 엎어버리고 다른 CPU Core가 해야 할 일과 관련된 데이터를 복사해야 하니까~~~
이렇기 때문에 비슷한 Job(프로그램, 또는 Process)에 대해서 L2 Cache를 같이 사용하도록 2개씩 쌍으로 할당하는 것이 최고의 성능을 낼 수 있다.
그럴 일은 없겠지만, 만약 논리 쓰레드 3개가 1개의 L2 Cache를 공유하는 CPU 제품이 있다면 3개씩 쌍으로 할당해야 최고의 성능을 낼 수 있다. (이것은 그냥 가정이다)
내 생각에는 처음부터 Intel x86 CPU가 Hyper Threading 구조가 아니였다면, 즉 Logical Core가 L2 Cache Memory를 공유하지 않는 구조였다면 CPU Pinning 설정할 때 짝수로 설정해야 하는 제약도 없었을 것 같다.
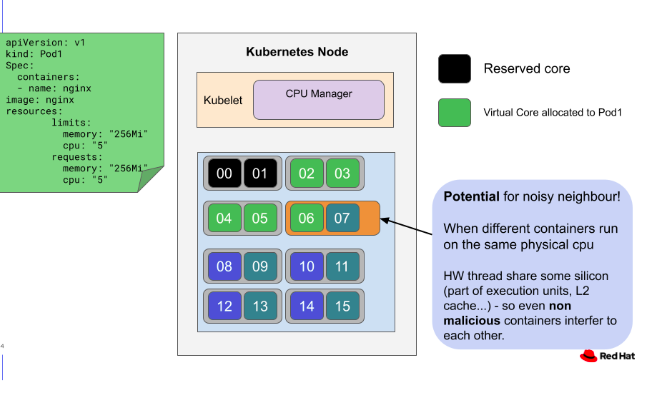
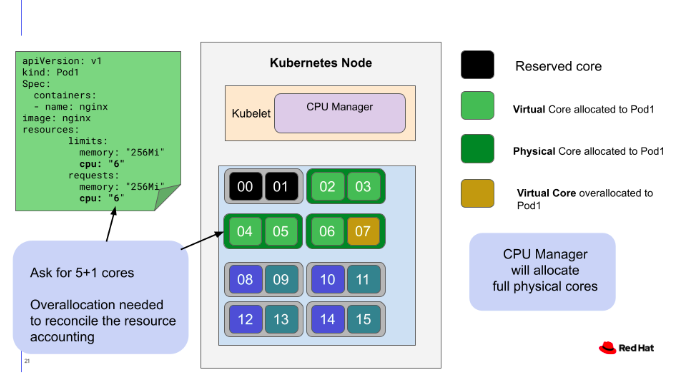
아래 그림은 Red Hat Web Docs에서 인용한 그림.
CPU Core 개수를 홀수로 설정하여 SMTAlignmentError 발생
CPU Core 개수를 짝수로 설정하여 CPU의 Virtual Thread가 L2 Cache 영역을 공유하지 않도록 함
Kubernetes, OCP(Openshift Container Platform)을 사용하다 보면, Resource에 대한 접근 권한 때문에 답답한 경우가 많다.
SCC(SecurityContext)를 잘 관리할 줄 알면, 제일 좋지만 급하게.. 그리고 간단하게 테스트만 하는 상황이라면,
아래와 같이 시스템의 모든 자원에 접근할 수 있도록 권한을 최고 수준(privileged)으로 올려주고 테스트하는 것이 정신 건강에 좋다.
(상용 서비스에서는 절대 이렇게 하면 안 된다. Test bed 같은 곳에서 잠깐 Feasibility check만 하고 Pod를 종료시킨다는 가정하에 사용할 것)
apiVersion: v1
kind: Pod
metadata:
name: my-example-pod
spec:
hostNetwork: true ## <-- 이 설정이 있으면, Pod 내부에서 Host Network이 보인다
## 예를 들어, Host OS의 eno3 network port를 보기 위해
## ifconfit eno3 명령 실행이 가능해진다.
containers:
...
securityContext:
privileged: true ## <-- 이렇게 하면 모든 자원에 접근 가능해진다.
...
securityContext: {}
...
만약, 극단적으로 Pod 내부에 있는 Process가 Host OS의 자원에 제약 없이 접근하고 싶다면 아래 예제 YAML처럼 권한 설정을 하면 된다. 이렇게 하면, Pod 내부에서 Pod 밖(즉 Host OS)의 IP network 자원, TCP Stack, IPC, ProcessID(PID) 등에 자유롭게 접근할 수 있다.
다시 한번 강조하지만, 위와 같이 securityContext.privileged: true 설정된 Pod를 상용 서비스를 제공하는 클러스터에서 구동한 상태로 오래 방치하면 결국 해커의 먹이감이 된다. 꼭 10분~20분 정도 테스트만 하고 바로 Pod를 종료(삭제)해야 한다.
아래 내용은 참고용으로만 볼 것!!!
DaemonSet으로 구동하는 Pod들은 securityContext 값이 privileged 으로 설정된 경우가 많다.
왜냐하면 이런 DaemonSet으로 구동된 Pod들은 각 노드에서 Host 자원에 접근해야 하는 경우가 있기 때문이다.
아래 예시를 보면 바로 이해가 될것이다.
Multus 배포 예시
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: multus
namespace: openshift-multus
... 중간 생략 ...
spec:
template:
... 중간 생략 ...
spec:
containers:
... 중간 생략 ...
securityContext:
privileged: true ## <-- 이 부분
... 중간 생략 ...
Openshift SDN 배포 예시
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: sdn
... 중간 생략 ...
spec:
template:
... 중간 생략 ...
spec:
containers:
... 중간 생략 ...
securityContext:
privileged: true ## <-- 이 부분
... 중간 생략 ...
내 생각에는 Node 장애가 발생했을 때, 빠르게 Pod가 장애가 발생한 Node에서 종료 처리되고 다른 Node로 스케쥴링되게 하려면, 300초로 설정된 값을 1초로 줄이면 되지 않을까하는 상상을 해본다.
시간 여유가 있을 때, 한번 1초로 변경하고 Node를 다운시켜서 테스트해봐야겠다.
참고: 쿠버네티스는 사용자나 컨트롤러에서 명시적으로 설정하지 않았다면, 자동으로 node.kubernetes.io/not-ready 와 node.kubernetes.io/unreachable 에 대해 tolerationSeconds=300 으로 톨러레이션을 추가한다. 자동으로 추가된 이 톨러레이션은 이러한 문제 중 하나가 감지된 후 5분 동안 파드가 노드에 바인딩된 상태를 유지함을 의미한다.
Kubernetes를 사용하다보면, Pod가 Terminating 상태에서 종료(즉, Pod의 삭제)되지 않고 계속 머물러있는 경우가 종종 발생한다.
이렇게 Pod의 Terminating 교착 상태가 된 원인은 정확히 알 수는 없고,
단지 이런 경우에 Pod를 종료시킬 수 없어서 당혹스럽다.
Ian Miell 이라는 사람이 상황별로 교착 상태에 빠진 Pod를 종료하는 방법을 정리한 Web Docs가 있어서 나한테 맞게 다시 메모를 해봤다.
$ kubectl delete -n istio-system deployment grafana
##
## 위 delete 명령을 수행 후, 1분이 넘도록 Pod가 Terminating 상태라면
## 이 Pod는 계속 Terminating 상태로 남고, 아래 예시처럼 Delete되지 않을 것이다.
##
$ kubectl get -A pod
NAMESPACE NAME READY STATUS RESTARTS AGE
istio-system grafana-68cc7d6d78-7kjw8 1/1 Terminating 0 37d
... 중간 생략 ...
$
위 현상을 세분화해서 해결 방법을 설명해보겠다.
Pod의 상세 정보를 확인
##
## (A) 강제로 Pod를 삭제하는 방법
##
$ kubectl delete pods <pod> --grace-period=0 --force
## 웬만하면, 위 명령으로 Pod가 삭제되지만
## 만약 계속 Pod의 찌끄러기가 남아 있다면, 아래 (B) 절차를 추가로 수행해야 한다.
##
## (B) 위 명령을 수행하고도 Pod이 Stuck 상태 또는 Unknown 상태로 남아 있다면
## 아래의 방법으로 Pod를 끝장낼 수 있다.
##
$ kubectl patch pod <pod> -p '{"metadata":{"finalizers":null}}'
Reference
Kubernetes.io에 Pod의 강제 종료에 대한 상세한 설명을 있으니, 시간이 있다면 꼼꼼히 읽어보면 도움이 된다.
##
## 채용 관련 글
##
제가 일하고 있는 기업 부설연구소에서 저와 같이 연구/개발할 동료를 찾고 있습니다.
(이곳은 개인 블로그라서 기업 이름은 기재하지 않겠습니다. E-mail로 문의주시면 자세한 정보를 공유하겠습니다.)
근무지 위치:
서울시 서초구 서초동, 3호선 남부터미널역 근처 (전철역 출구에서 회사 입구까지 도보로 328m)
필요한 지식 (아래 내용 중에서 70% 정도를 미리 알고 있다면 빠르게 협업할 수 있음):
- 운영체제 (학부 3~4학년 때, 컴퓨터공학 운영체제 과목에서 배운 지식 수준):
예를 들어, Processor, Process 생성(Fork)/종료, Memory, 동시성, 병렬처리, OS kernel driver
- Linux OS에서 IPC 구현이 가능
예를 들어, MSGQ, SHM, Named PIPE 등 활용하여 Process간 Comm.하는 기능 구현이 가능하면 됨.
- Algorithm(C언어, C++ 언어로 구현 가능해야 함)
예를 들어, Hashtable, B-Tree, Qsort 정도를 C 또는 C++로 구현할 수 있을 정도
- Network 패킷 처리 지식(Layer 2 ~ 4, Layer 7)
예를 들어, DHCP Server/Client의 주요 Feature를 구현할 정도의 능력이 있으면 됨.
- Netfilter, eBPF 등 (IP packet hooking, ethernet packet 처리, UDP/TCP packet 처리)
- IETF RFC 문서를 잘 읽고 이해하는 능력 ^^
# 위에 열거한 내용 외에도 제가 여기 블로그에 적은 내용들이 대부분 업무하면서 관련이 있는 주제를 기록한 것이라서
# 이 블로그에 있는 내용들을 잘 알고 있다면, 저희 연구소에 와서 연구/개발 업무를 수행함에 있어서 어려움이 없을 겁니다.
회사에서 사용하는 프로그래밍 언어:
- 프로그래밍 언어: C, C++, Go
(참고: 아직 연구소 동료들이 Rust를 사용하진 않습니다만, 새 언어로써 Rust를 사용하는 것을 고려하는 중)
근무 시간:
- 출근: 8~10시 사이에서 자유롭게 선택
- 퇴근: 8시간 근무 후 퇴근 (오후 5시 ~ 7시 사이)
- 야근 여부: 거의 없음 (내 경우, 올해 상반기 6개월간 7시 이후에 퇴근한 경우가 2회 있었음)
- 회식 여부: 자유 (1년에 2회 정도 회식하는데, 본인이 집에 가고 싶으면 회식에 안 감. 왜 참석 안 하는지 묻지도 않음)
외근 여부:
- 신규 프로젝트 멤버 -> 외근 전혀 하지 않음 (나는 신규 프로젝트만 참여해서 지난 1년 동안 한번도 외근 없었음)
- 상용 프로젝트 멤버 -> 1년에 5회 미만 정도로 외근
팀 워크샵 여부:
- 팀 워크샵 자체를 진행하지 않음. (워크샵 참석하는 거 싫어하는 개발자 환영 ^^)
연락처:
- "sejong.jeonjo@gmail.com" # 궁금한 점은 이 연락처로 문의주세요.
- 블로그 비밀 댓글 (제가 하루에 한번씩 댓글 확인하고 있음)
원하는 인재상:
- 우리 부설연구소는 "긴 호흡으로 프로젝트를 진행"하기 때문에 최소 2년간 한 가지 주제를 꾸준하게 연구/개발할 수 있는 개발자를 원함.
- 우리 부설연구소는 자주적으로 연구 주제를 찾아서 업무를 하기 때문에 능동적으로 생각하고 행동하는 동료를 원함.
- 차분하게 연구 주제에 몰입하고, 해법을 찾는 것을 즐기는 사람.
내가 느끼는 우리 연구소의 장점:
- 갑/을 관계가 없음. (제가 근무하고 있는 연구소는 SI업종이 아니라서 갑/을 회사 개념이 없음)
- 연구소 자체적으로 연구 주제를 발굴하고 시스템을 개발하기 때문에 개발 일정에 대한 스트레스가 적음
- 빌딩 전체를 우리 회사가 사용하므로 분위기가 산만하지 않음.
- 근처에 예술의전당, 우면산 둘레길이 있어서 점심 시간에 산책하기 좋음 ^^
- 연구소 동료들 매너가 Good (2년간 일하면서 한번도 감정에 스크레치 생기거나 얼굴 붉히며 싸운 적 없음 ^^)
Istio를 사용해서 Pod간 Traffic을 제어하다보면, 특정 Pod의 특정 TCP Port는 Proxy 처리에서 제외(Exclude)시키고 싶을 때가 있다.
(즉, Istio Enovy Proxy Container를 경유하지 않고, 바로 다른 연동할 Pod로 TCP Traffic을 보낸다는 뜻)
아마, 대부분 HTTP가 아닌 회사 내부에서 자체적으로 Protocol을 정해놓고 연동하는 Traffic 들이 대부분일 듯.
또는 NATS, Kafka 같은 Message Broker와 연동하는 경우에도 굳이 Service Mesh를 사용할 일이 없다.
왜냐하면 NATS, Kafka는 원래 메시지 분산 처리를 할 수 있도록 설계되어 있으니까 굳이 Istio의 제어를 받지 않아도 된다.
만약, TCP Port 50001를 사용하는 TCP Traffic을 Istio Envoy Proxy를 경유하지 않고, Main App Container (A)에서 바로 다른 Main App Container(B)에게 보내려면 아래와 같이 Pod에 Exclude Annotation을 설정한다.