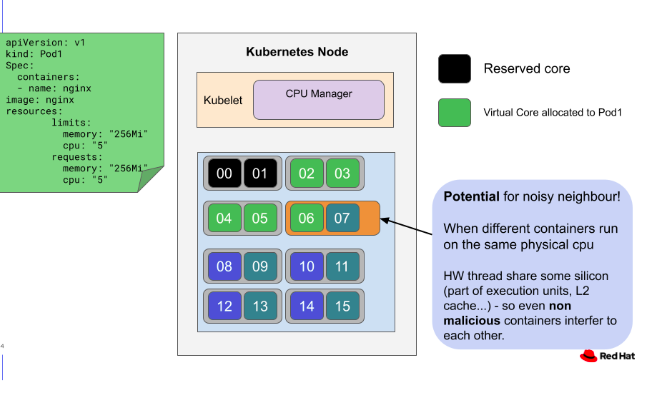
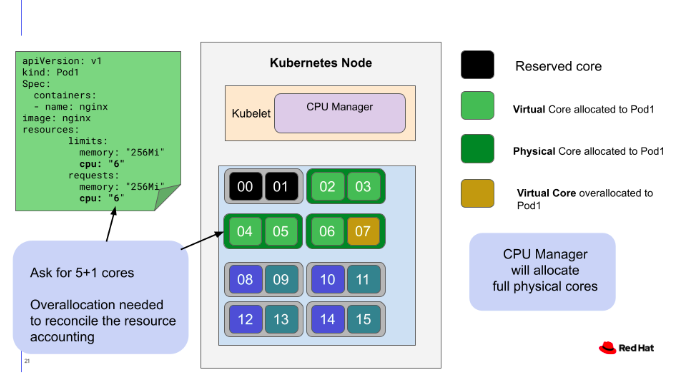
Istio를 사용해서 Pod간 Traffic을 제어하다보면, 특정 Pod의 특정 TCP Port는 Proxy 처리에서 제외(Exclude)시키고 싶을 때가 있다.
(즉, Istio Enovy Proxy Container를 경유하지 않고, 바로 다른 연동할 Pod로 TCP Traffic을 보낸다는 뜻)
아마, 대부분 HTTP가 아닌 회사 내부에서 자체적으로 Protocol을 정해놓고 연동하는 Traffic 들이 대부분일 듯.
또는 NATS, Kafka 같은 Message Broker와 연동하는 경우에도 굳이 Service Mesh를 사용할 일이 없다.
왜냐하면 NATS, Kafka는 원래 메시지 분산 처리를 할 수 있도록 설계되어 있으니까 굳이 Istio의 제어를 받지 않아도 된다.
만약, TCP Port 50001를 사용하는 TCP Traffic을 Istio Envoy Proxy를 경유하지 않고, Main App Container (A)에서 바로 다른 Main App Container(B)에게 보내려면 아래와 같이 Pod에 Exclude Annotation을 설정한다.
| apiVersion: apps/v1 |
| kind: StatefulSet |
| metadata: |
| name: myapp |
| |
| ... 중간 생략 ... |
| |
| spec: |
| template: |
| metadata: |
| annotations: |
| sidecar.istio.io/inject: "true" |
| traffic.sidecar.istio.io/excludeInboundPorts: "34432,50001,50002,50003,50100,50102,50103,50200,50201,50203,50300,50301,50302" |
| traffic.sidecar.istio.io/excludeOutboundPorts: "34432,50001,50002,50003,50100,50102,50103,50200,50201,50203,50300,50301,50302" |