참고 문서: https://pr0gr4m.github.io/linux/kernel/netfilter/ 이론 설명과 함께 잘 동작하는 예시가 있어서 쉽게 이해할 수 있다. 아래는 위 블로그의 끝 부분에 있는 HTTP Traffic만 선별하여 Drop하는 예제 코드인데, 그냥 이 예제 코드만 봐도 이해할 수 있을 것이다.
iptables는 다수의 Chain(예: PREROUTING, INPUT, OUTPUT, POSTROUTING, FORWARD)과 그 Chain에 정의된 Rule, 그리고 각 Chain에는 다수의 Table(raw, mangle, nat, filter, security)이 포함되어 있다.
Iptables의 Chain 종류와 Table 종류
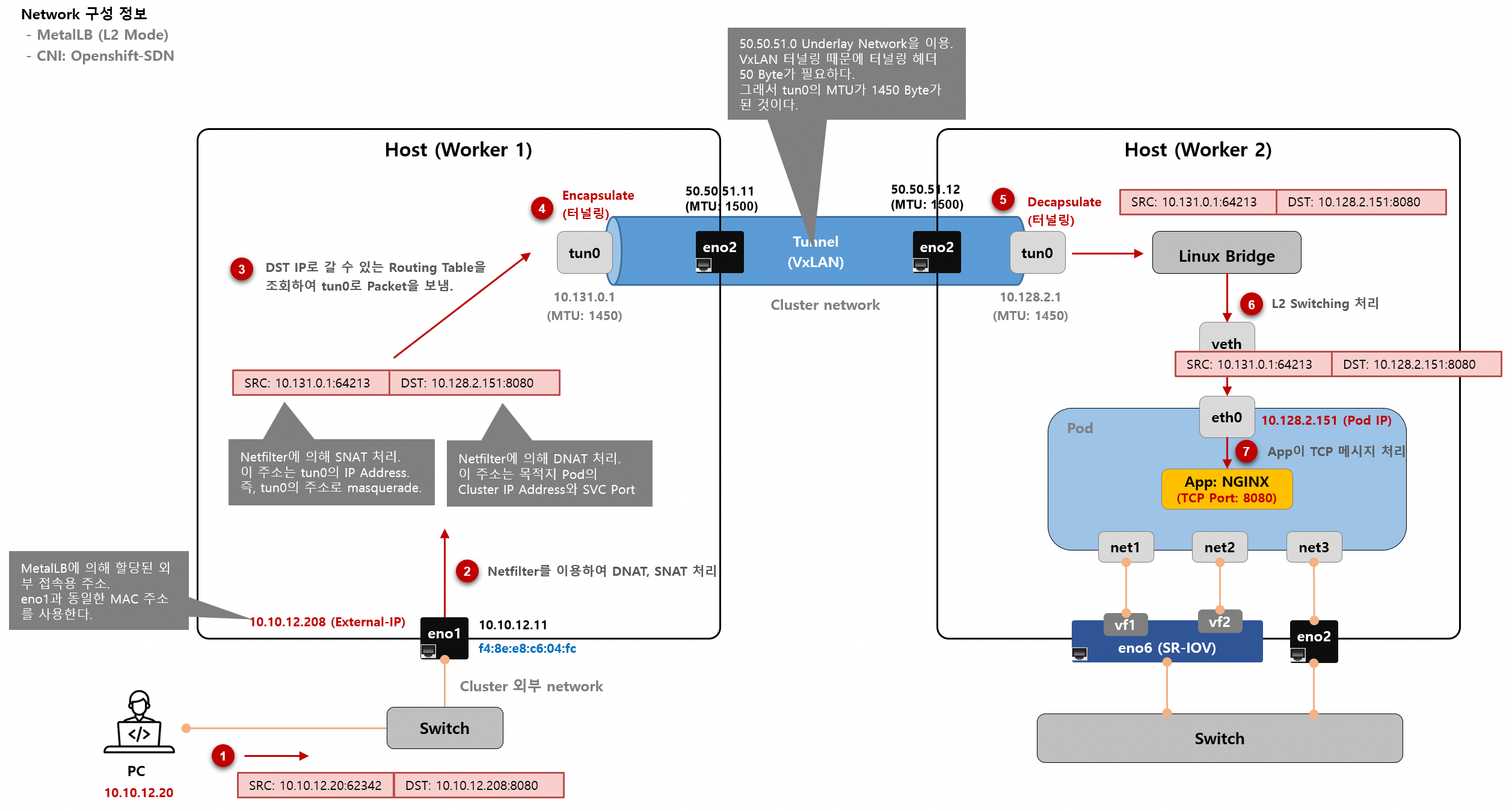
IP Packet이 유입된 이후에 아래 그림과 같이 패킷의 L2, L3, L4 Header를 조작하거나, Header의 내용을 보면서 IP Packet을 다음 Chain에서 처리하게 할지, 아니면 Client(Sender)로 되돌려 보낼지를 처리한다.
IPTables Chains Order Scheme (from https://jimmysong.io/en/blog/sidecar-injection-iptables-and-traffic-routing/)
위 그림을 볼 때, 주의할 점은 노란색 메모장 같은 라벨이 붙은 table에서는 IP packet을 조작한다는 것이다. 그리고 filter 같은 table에서는 IP packet을 열람만하고 조작하지 않는다.
그리고, 아래 그림은 istio의 envoy proxy container와 app container가 어떻게 IP Traffic을 전달하는지 보여준다. 이때도 역시 iptables가 IP traffic의 전달에 관여한다.
[action] 전체 체인에 대한 정책을 지정 / -A , -L , -D , -F 등 대문자 옵션이 해당한다.
[chain] 일반적 필터링에 속하는 INPUT.OUTPUT.FORWARD가 있으며 NAT테이블에는 POSTROUTING / PREROUTING / OUTPUT 이 있다.
[pattern] 세부규칙을 지정하는 것으로 소문자 옵션 -s / -p /-d 등이 이에 해당한다.
[target] 정책을 지정하는 것이며 DROP / ACCEPT / LOG 등등이 있다.
iptables 명령 예시
Example - A
$ iptables -t filter
-A INPUT # 들어오는 패킷에 대한 필터링
-i eth0 # eth0 네트워크 아답터로 들어오는 패킷들이 대상임
-p ICMP # 프로토콜이 ICMP이면
-j DROP # 위 조건을 만족하는 패킷을 소멸(삭제)
Example - B
$ iptables -t filter
-A INPUT # 들어오는 패킷에 대한 필터링
-i eth0 # eth0 네트워크 아답터로 들어오는 패킷들이 대상임
-o eth0 # eth0 네트워크 아답터로 나가는는(output) 패킷들이 대상임
-p TCP # 프로토콜이 TCP이면
--dport 22 # destination port가 22번이면
--sport 39321 # source port가 39321번이면
-j ACCEPT # 위 조건을 만족하는 패킷을 Accept
iptables 사용하기
iptables는 사용하는 방법은 크게 두가지가 있다.
첫번째는 전체 체인에 대한 설정이고,
두번째는 각 체인에 대한 규칙을 사용하는 방법이다.
체인에 대한 동작설정은 대문자 옵션을 사용하고 체인에 대한 세부규칙은 소문자 옵션을 사용한다.
체인 전체옵션 설명
-N 새로운 체인을 만든다 -X 비어있는 체인을 제거한다 -P 체인의 정책을 설정한다 -L 현재 체인의 정책을 보여준다 -F 체인의 규칙을 제거한다 *체인 동작옵션 설명 (내부규칙을 뜻함) -A 체인에 새로운 규칙을 추가한다. 해당체인에 마지막규칙으로 등록된다. -t 가 filter 인 경우 INPUT, FORWARD 사용가능 -t 가 nat 인 경우 POSTROUTING , PREROUTING 사용가능 -I 체인에 규칙을 맨 첫부분에 등록한다. -R 체인의 규칙을 교환한다. -D 체인의 규칙을 제거한다
$ iptables -A INPUT -s 192.168.10.0/24 -j DROP # 192.168.10.0/24 네크워크에서 들어오는 패킷들을 모두 DROP한다.
# -j 옵션에 대해 ACCEPT | DROP | DENY | REDIRECT 등등 설정
$ iptables -A INPUT -s 192.168.10.20 -j DENY # 192.168.10.20으로 들어오는 패킷에 대해서 거부한다.
-p (프로토콜의 지정) (예) -p ! TCP # TCP 프로토콜이 아닌경우를 뜻함
-i (--in-interface) 패킷이 들어오는 인터페이스를 지정 INPUT / FORWARD 체인에서 사용 -t nat 이면 PREROUTING에서만 사용 가능
-o ('--out-interface') 패킷이 나가는 인터페이스를 지정 OUTPUT / FORWARD 체인에서 사용 -t nat 이면 POSTROUTING에서만 사용 가능
-t (--table) 테이블 선택의 의미 -t filter / -t nat / -t mangle 세가지 선택을 할수 있다.
iptables 의 추가 옵션 설정하기
-p 같은 프로토콜 관련 옵션들의 기능에 대한 세부적인 추가 옵션을 제공한다. --sport 발신지에서의 하나의 포트나 포트범위를 지정한다. --dport 도착지에서의 포트를 지정한다. --tcp-flags 플래그를 지정하는 옵션이다. 첫번째는 검사하고자 하는 지시자 리스트 . 두번째는 지시자에 어떻게 할것인가를 설정
$ iptables -A INPUT -p tcp --tcp-flag ALL SYN<ACK -j DENY # 모든플래그를 검사(ALL의 의미는 SYS,ACK,FIN,RST,URG,PSH를 의미)SYN 과 ACK만 거부한다.
정책(Rule) 확인법
ping test를 이용하여 traffic policy를 확인할 수 있다.
$ ping localhost # 127.0.0.1로 핑 보내기
## 정상적으로 ping packet이 전송되는 것을 확인한다.
$ iptable -A INPUT -s 127.0.0.1 -p icmp -j DROP # 출발지가 127.0.0.1 이며 프로토콜 icmp 사용해 들어오는 패킷을 DROP 한다.
$ ping localhost
## DROP 정책이 정상적으로 적용되었다면, ping이 되지 않을 것이다.
정책(Rule) 지우기
우선, 지우고자 하는 정책을 확인하고, -D 옵션을 이용하여 해당 정책을 지운다.
$ iptables -L --line # 정책 순서대로 리스트 번호가 설정되어 보여짐
## 개별 정책 지우기 (-D)
## iptables -D [해당정책] [리스트번호]
$ iptables -t nat -D PREROUTING 2
## 전체 정책 초기화 (-F)
$ iptables -F INPUT # INPUT체인에 부여된 정책 모두 제거
## root 사용자로 변경
$ sudo -s
## 자동 복구를 위한 관련 SW 패키지 설치
$ apt install iptables-persistent
## 아래와 같이 /etc/iptables 폴더가 생성되었는지 확인
$ ls -al /etc/iptables/
## netfilter-persistent 서비스 상태를 확인
$ systemctl status netfilter-persistent
$ systemctl is-enabled netfilter-persistent
## 테스트를 위해 아래와 같이 Rule을 추가해보고, OS Reboot해본다.
$ iptables -A POSTROUTING -t nat -o br-ex -s 172.16.0.0/16 -j MASQUERADE
##
## OS Reboot 완료 후, iptables 명령으로 netfilter rule이 잘 복구되었는지 확인한다.
##
$ iptables-save | grep 172.16.0.0
## 아래 명령과 같이 'save' 서브 명령이 있는데,
## 지금까지 테스트해본 결과를 보면, 'save' 명령을 수행하지 않아도
## 그때그때 netfilter rule의 변화를 /etc/iptables 폴더에 반영하는 것 같다.
## (2023년 6월 기준으로 이렇게 동작하지만, 나중에 또 어떻게 바뀌지 모르니까 참고만 할 것 !)
$ netfilter-persistent save